Imagine you are the third judge at an art exhibition. The first two judges have already voted. You pick up the first dossier — a filter called Terminal Matrix, which renders any photograph as glowing green phosphor characters on a jet-black screen, like a vintage computer terminal.
Judge One — methodical, holistic — awarded it 79 out of 100. Judge Two — a strict statistician who measured actual pixel data — gave it a perfect score: 10 out of 10. The highest mark awarded to anything in the entire exhibition.
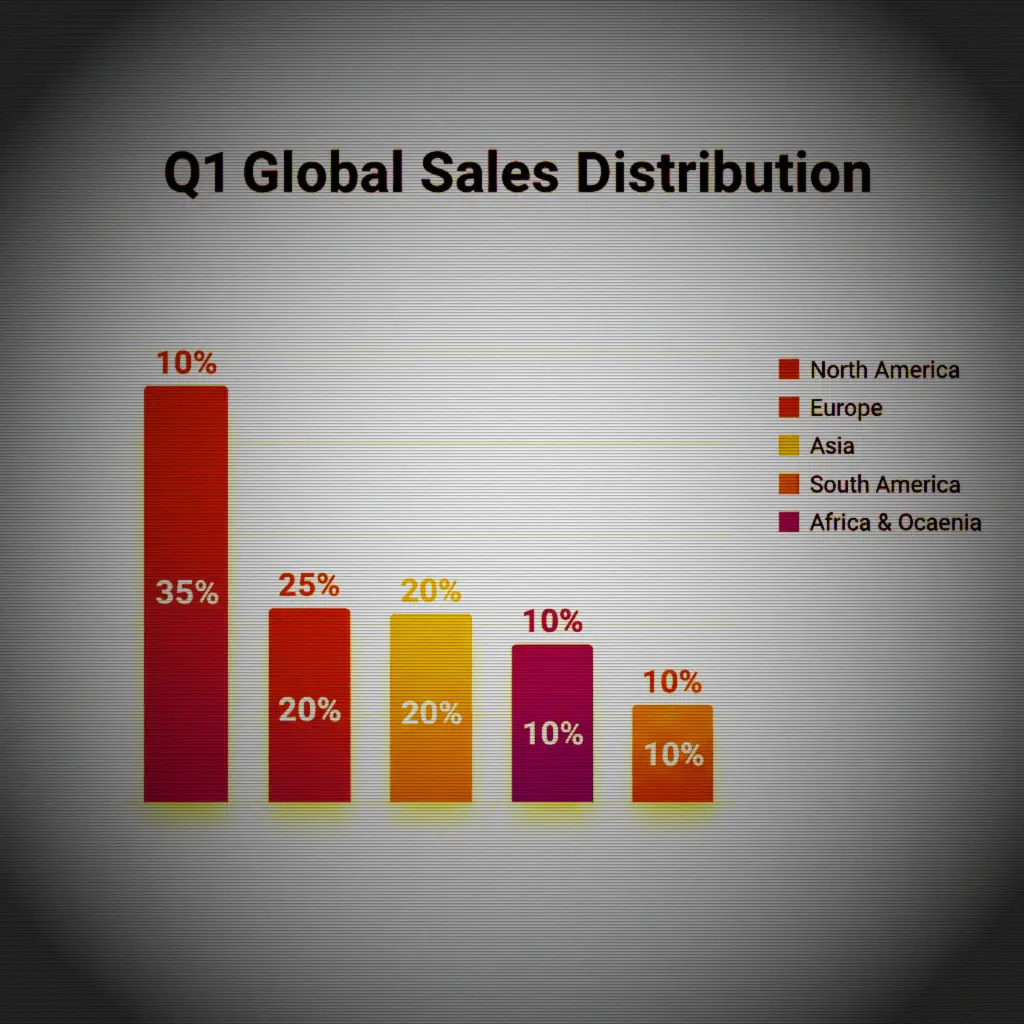
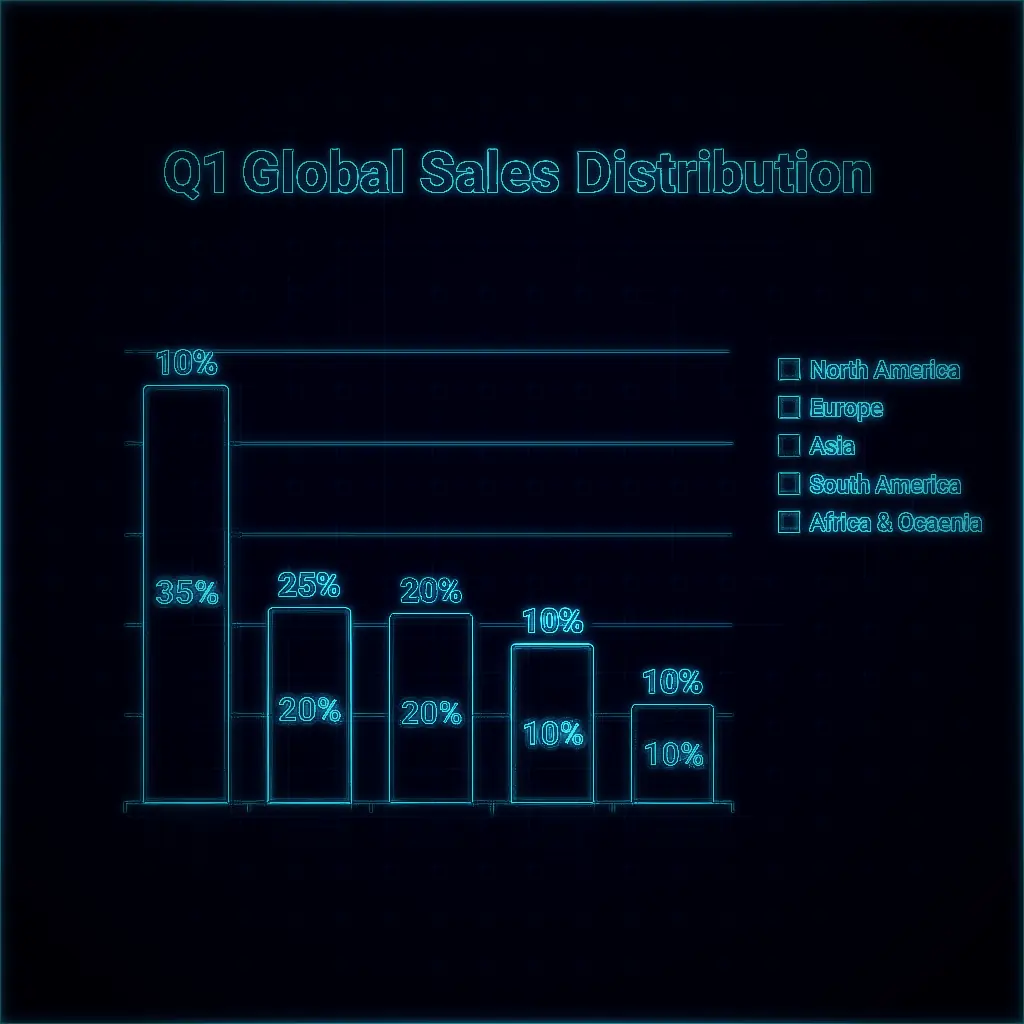
You study the output images carefully. You appreciate the atmospheric CRT glow, the phosphor-green portrait. But you also notice something the others missed: when this filter is applied to a bright sales chart, the light background turns the whole image into a sickly greenish wash instead of the crisp dark screen the concept demands. The filter has a blind spot. It only works in the dark.
You write: 6.6 out of 10. Rank: 22nd of 30.
Holistic Judge
Pixel Analyst
Medium Critic
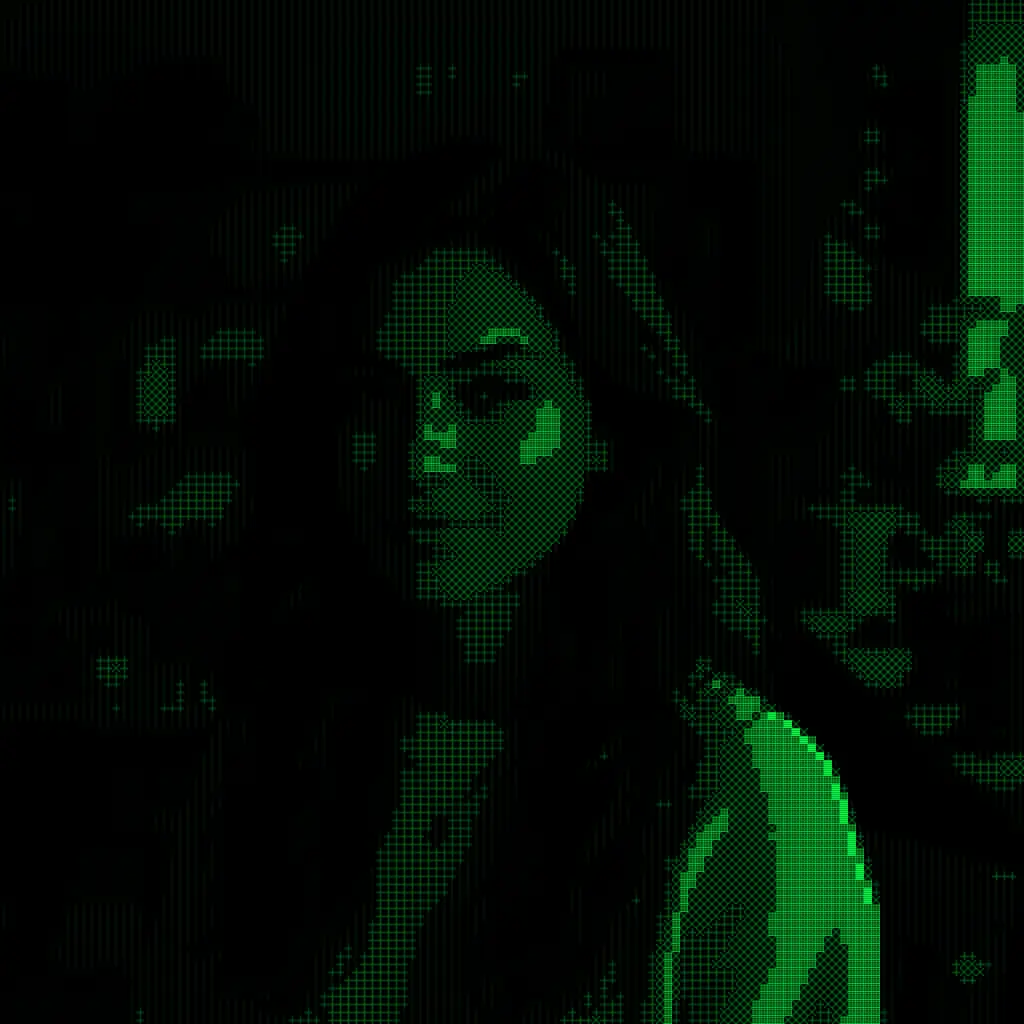

That gap — from a perfect score to the bottom third — is not a grading error. It is the entire story. Three artificial intelligences looked at the same thirty pieces of AI-generated art and came to dramatically different conclusions. Understanding why tells us something fundamental about how machine intelligence defines quality, and what it means to judge something good.